JSON是一种轻量级资料交换格式,其内容由属性和值所组成,因此也有易于阅读和处理的优势,JSON也是目前最为流行的C/S通讯方式。JavaEE的规范中制定了Java API for JSON Processing (JSON-P,JavaEE7+)和Java API for JSON Binding (JSON-B,JavaEE8+)规范,但是在JavaEE的request中无法直接获取JSON请求中的参数,需要借助MVC框架和第三方JSON解析库。
一、研究JSON解析特性的重要性
随着前后端分离的开发方式的兴起,基于JSON的请求变得越来越流行。为了能够防御来自JSON请求参数中的恶意攻击,WAF和RASP都逐渐的支持了JSON参数解析。也许是因为Java语言没有官方的JSON解析库,因此诞生了非常多的第三方JSON解析库,它们被广泛的运用于不同Web应用中,其中不乏号称性能天下第一、用户体量巨大且长期存在安全问题的fastjson(俗称bugson)。
JSON反序列化攻击是目前最为主流的JSON请求攻击方式,很少有人关注过JSON解析本身所包含的特性所带来的安全问题。
RASP和WAF为了能够支持JSON解析就必然会选择(自实现?)JSON解析库,但是如果我们一旦找出其使用的库存在的解析问题后就可以轻松绕过防护,即可轻松绕过基于参数解析的WAF和RASP部分依赖请求参数的防护功能。
似乎在大多数人的潜意识中已经认定了Java中的JSON解析库都会按照某一个标准去解析(fastjson第一个不服),因此不会存在什么安全风险,本文将从JSON解析的细节(不包含反序列化攻击)来讲解JSON解析库的特性,让我们进一步的去了解不同的解析库所带来的巨大差异。
JSON解析库列表:
| 名称 | 描述 |
|---|---|
| gson | gson是google开源的Java JSON解析库,也是如今主流的JSON解析库之一 |
| jackson | jackson是开源的高性能JSON解析库,也是Spring MVC默认使用的JSON解析库 |
| fastjson | fastjson是阿里开源的JSON解析库,自称性能天下第一、API简单易用、也是目前主流的JSON解析库,但安全风险高 |
| fastjson2 | fastjson2是fastjson的升级版,同样号称“性能顶破天,支撑JSON解析下一个十年”的知名JSON解析库 |
| dsl-json | 性能最强但用户量极小(应该是因为DSL原因)的JSON解析库 |
| org.json | 上一个十年(2010年左右)最为流行的JSON解析库 |
| johnzon | TomEE中的JWS-RS默认使用的JSON解析库,性能非常差 |
二、注释符
部分JSON解析库支持在JSON中插入注释符,注释符中的任何字符不会被解析。
- gson支持
/**/(多行)、//(单行)、#(单行)这三类注释符; - fastjson支持除
#以外的注释符; - fastjson2只支持
//注释符;
| payload | gson | jackson | fastjson | fastjson2 | dsl-json | org.json | johnzon |
|---|---|---|---|---|---|---|---|
| /**/(多行) | √ | √ | |||||
| //(单行) | √ | √ | √ | ||||
| #(单行) | √ |
三、首个Unicode空白符
首个Unicode空白字符指的是{}、[]、注释符之前的可被JSON库解析的有效字符,这个特性可用来绕过某些解析JSON请求时不看Content-Type,只看输入流是否是以{或者[开始的字符(针对一些特殊的字符trim也没用)的RASP或者WAF,除了使用特殊字符以外,某些场景下其实还可以使用注释符来代替这些特殊的Unicode字符。
- 统计表中不包含正常的用于表示空白符的
\t、\n、\r; - fastjson支持
0x00; - fastjson和org.json支持
>0,<=32的ASCII字符; - dsl-json支持较多大于127的Unicode字符;
表 - 首个Unicode字符解析:
| Unicode | gson | jackson | fastjson | fastjson2 | dsl-json | org.json | johnzon |
|---|---|---|---|---|---|---|---|
| 0 | √ | ||||||
| 1-7 | √ | √ | |||||
| 8 | √ | √ | √ | ||||
| 11 | √ | √ | √ | ||||
| 12 | √ | √ | √ | √ | |||
| 14-31 | √ | √ | |||||
| 127 | √ | ||||||
| 5760 | √ | ||||||
| 8192 - 8202 | √ | ||||||
| 8232 - 8233 | √ | ||||||
| 8239 | √ | ||||||
| 8287 | √ | ||||||
| 12288 | √ | ||||||
| 65279 | √ | √ | √ | ||||
| 65534 | √ |
从解析情况来看,有一些大于127的Unicode字符也能被某些JSON解析库解析,这是如何做到的呢?
3.1 fastjson2
fastjson2支持的空白符比较常规,com.alibaba.fastjson2.JSONReader类中的SPACE代码中定义了允许换行的特殊字符:
static final long SPACE = (1L << ' ') | (1L << '\n') | (1L << '\r') | (1L << '\f') | (1L << '\t') | (1L << '\b');除此之外,还有\uFFFE(编码为65534)和\uFEFF(编码为65279),这两个字符可以当做空白符(这两个特殊字符是用来表示UTF16中的BOM,byte order mark 字节序标记),如下图:
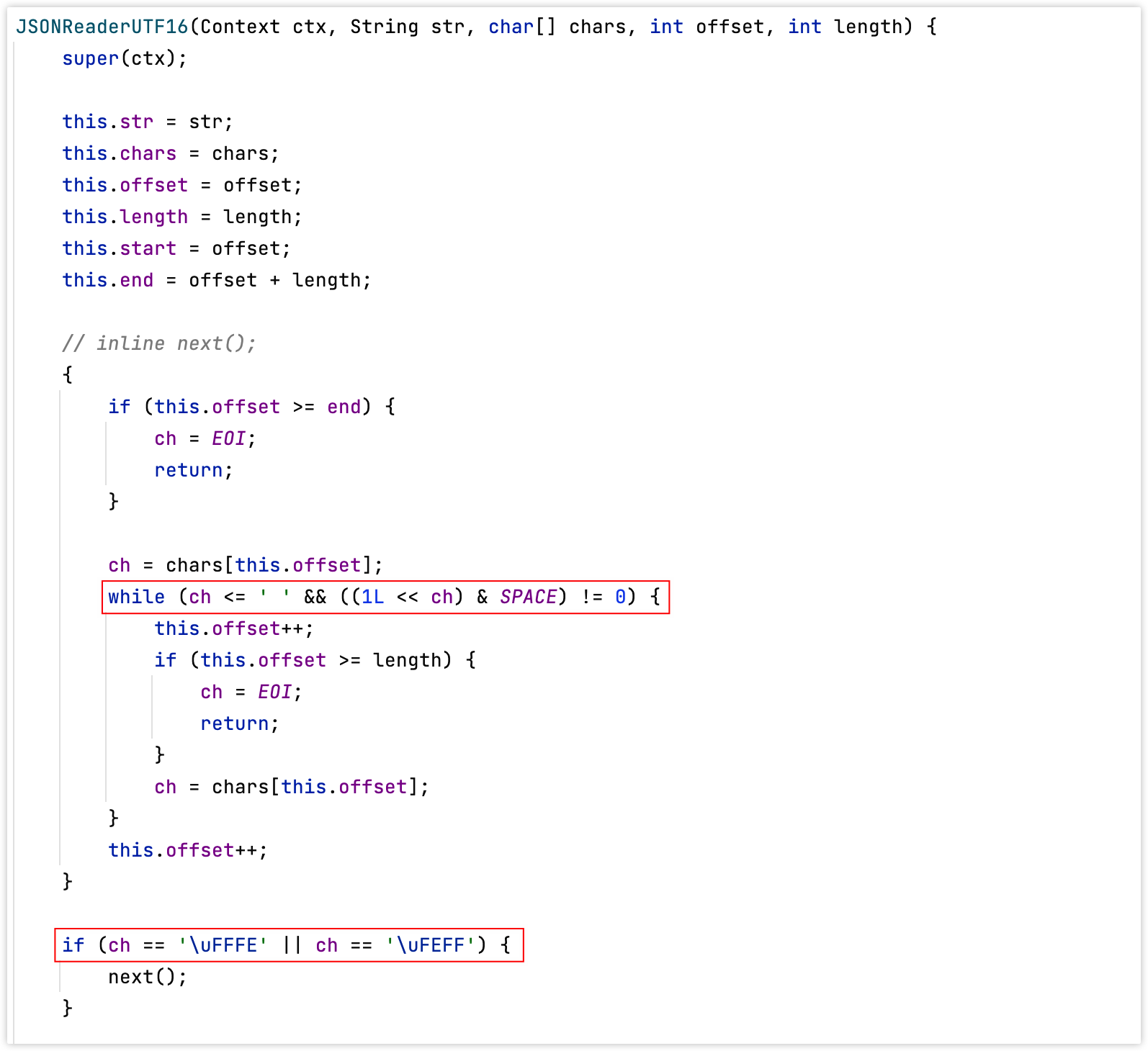
在UTF-16中,字节顺序标记被放置为文件或文字符串流的第一个字符,以标示在此文件或文字符串流中,以所有十六比特为单位的字码的端序(字节顺序)。如果试图用错误的字节顺序来读取这个流,字节将被调换,从而产生字符U+FFFE,这个字符被Unicode定义为“非字符”,不应该出现在文本中。例如,值为U+FFFE的码位被保证将不会被指定成一个统一码字符。这意味着0xFF、0xFE将只能被解释成小端序中的U+FEFF(因为不可能是大端序中的U+FFFE)。
表 - 不同编码的字节顺序标记
| 编码 | 十六进制 | 十进制 | byte[] |
|---|---|---|---|
| UTF-8 | EF BB BF | 239 187 191 | -17 -69 -65 |
| UTF-16 BE | FE FF | 254 255 | -2 -1 |
| UTF-16 LE | FF FE | 255 254 | -1 -2 |
| UTF-32 BE | 00 00 FE FF | 0 0 254 255 | 0 0 -2 -1 |
| UTF-32 LE | FF FE 00 00 | 255 254 0 0 | -1 -2 0 0 |
| UTF-7 | 2B 2F 76 | 43 47 118 | 43 47 118 |
| UTF-1 | F7 64 4C | 247 100 76 | -9 100 76 |
| UTF-EBCDIC | DD 73 66 73 | 221 115 102 115 | -35 115 102 115 |
| SCSU | 0E FE FF | 14 254 255 | 14 -2 -1 |
| BOCU-1 | FB EE 28 | 251 238 40 | -5 -18 40 |
| GB18030 | 84 31 95 33 | 132 49 149 51 | -124 49 -107 51 |
因此gson/fastjson/fastjson2/支持\uFEFF也就显得比较合理了,但实际情况并不会根据BOM解析对应的编码。
3.2 dsl-json
dsl-json使用的是boolean[256]来存储所有空白符,对应的是byte(-128到127),last + 128是为了去除符号,也就是说只要byte位不在空白符所对应的取值区间,那么是不会有任何问题的。
图 - dsl-json空白符取值范围:
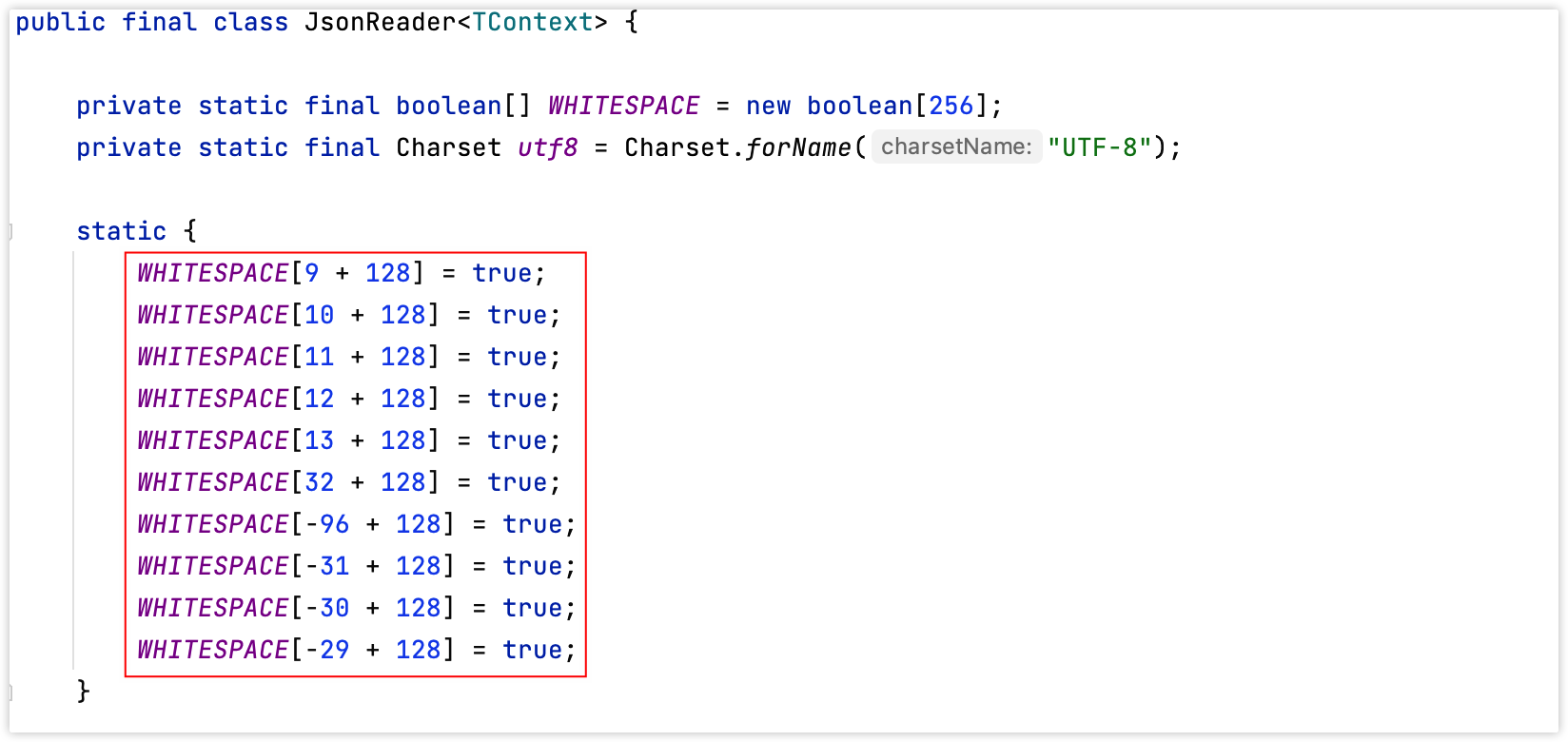
由上图可知,dsl-json只是约束了部分的byte字符为空白符,看似并不存在任何问题,但是JSON必须是一个字符串,而字符串本质上是由char组成的,而char又是由byte数组编码而来的,而一个UTF-8字符是由多个字节组成的,因此当我们使用一个大于127的Unicode字符时会由多个字节所表示。
比如:Unicode字符က(char,对应的编码为4096),က这个字符转换成byte后变成了3位的byte数组,即:-31 -128 -128,而dsl-json解析时会将byte位作为最小单元而不是char(char),而-31这个字节正好符合了第一个if判断,如下图:
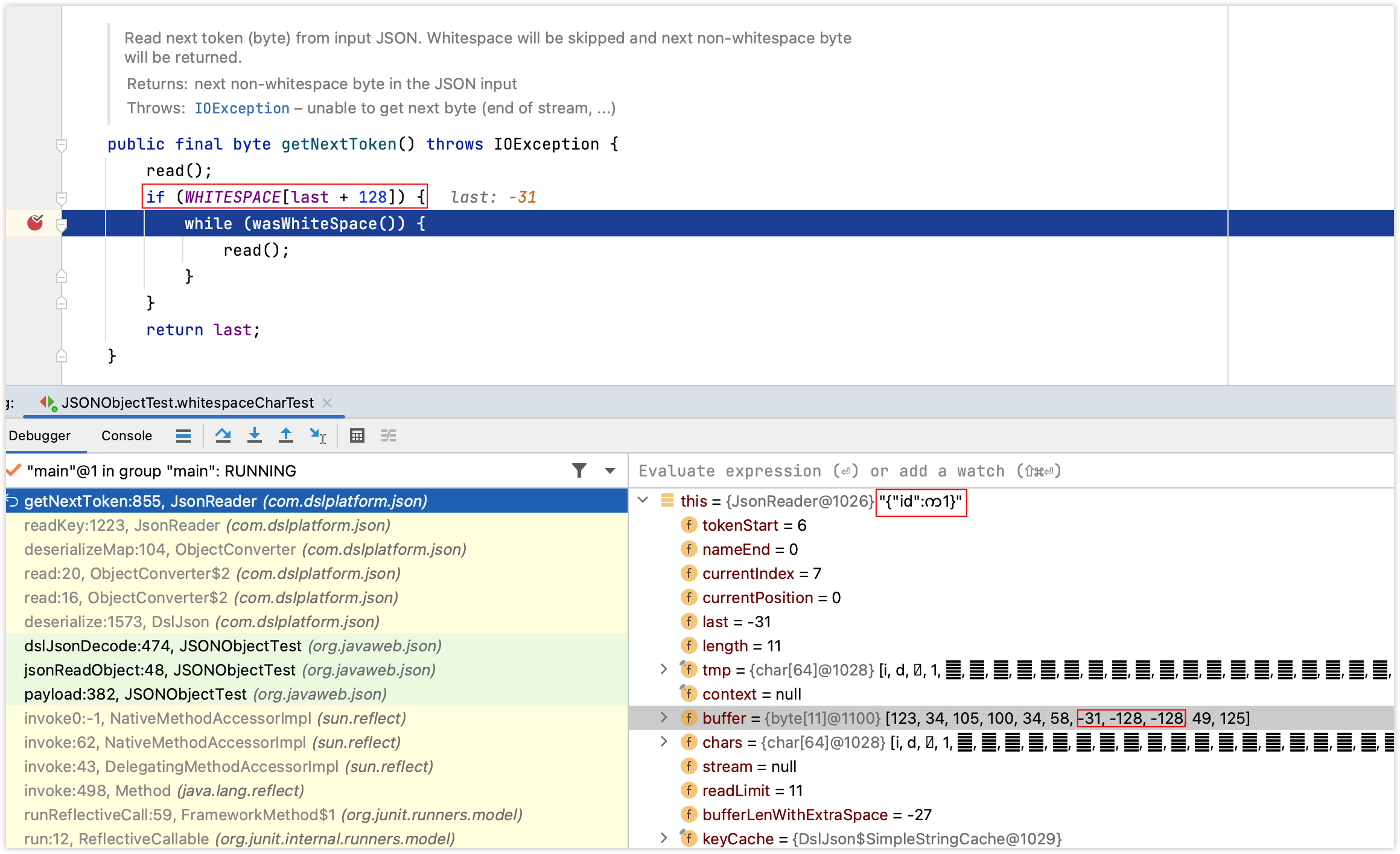
显然,wasWhiteSpace这个方法的逻辑关系到是否会将က处理,因为目前只是处理了-31,后面的-128 -128因此需要进入该方法进一步的分析,如下图:
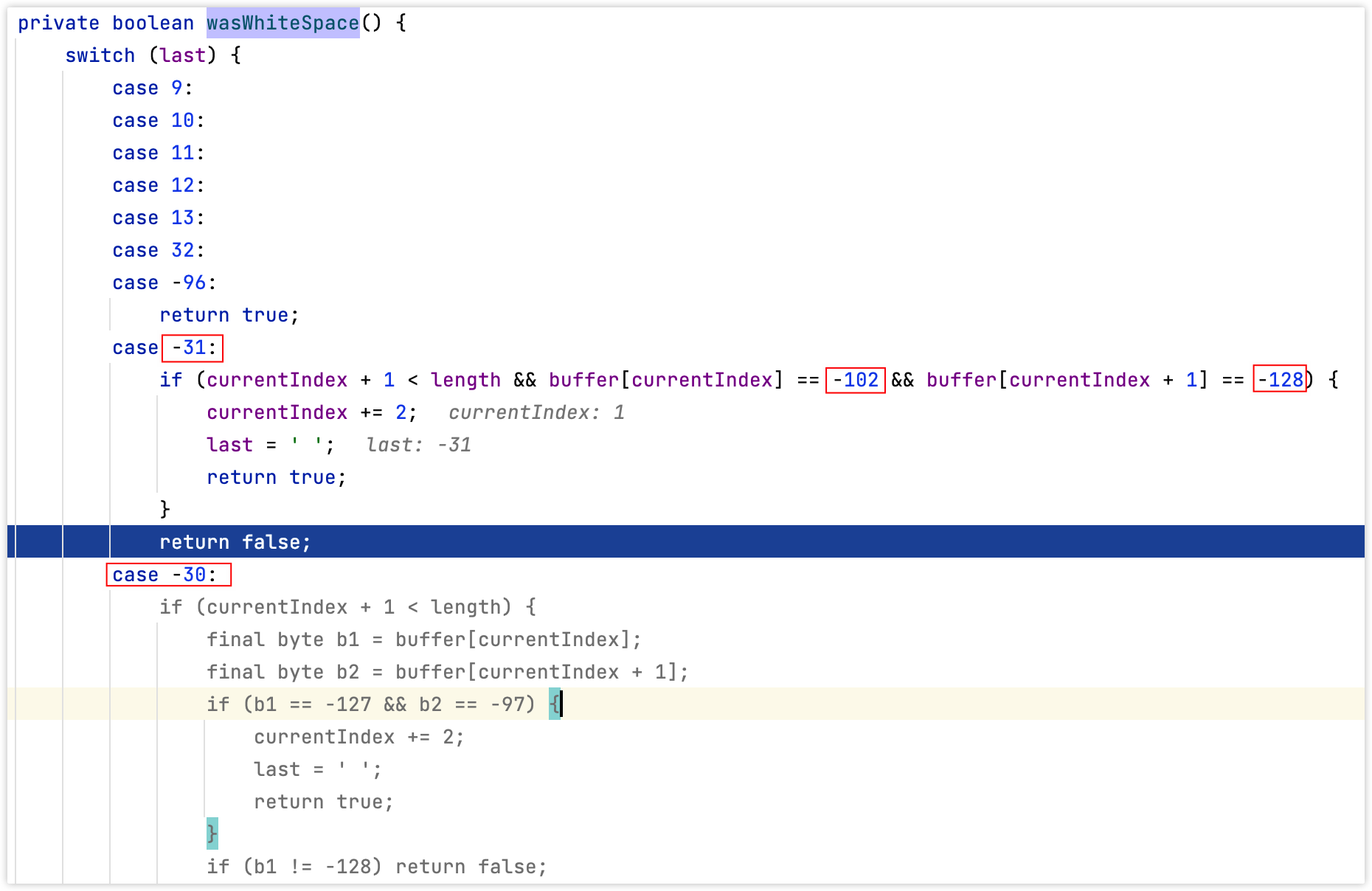
分析-31的处理逻辑后得知,后面的两个byte位必须是-102和-128(也就是编码为5760的字符)才能被当做是空白符,而-31 -128 -128并不符合这个条件,因此က并不能当做空白符使用。
不过这里可以用其他的字符代替,例如:编码为8192的Unicode字符(byte为-30 -128 -128),完美符合上图的case -30的逻辑判断,因此dsl-json中的字符编码8192支持当做空白符解析,表格中列举的其他的字符同理。
四、引号
在标准的JSON中key、value(非整形)都需要使用使用引号引起来,在Java中默认使用"(双引号)来包裹key/value,但是存在一些特殊的库支持'(单引号)甚至是不使用任何单双引号来处理key和字符类型的value。
- fastjson、gson、org.json支持
'、"、无引号; - fastjson支持单双引号,无引号混用,但是fastjson不支持key、value都是引号;
- 支持单双引号的库都支持单双引号混用;
| payload | gson | jackson | fastjson | fastjson2 | dsl-json | org.json | johnzon |
|---|---|---|---|---|---|---|---|
| {‘id’: “1”} | √ | √ | √ | √ | |||
| {id: “1”} | √ | √ | √ | ||||
| {id: 2b} | √ | √ |
五、超大JSON
超大JSON指的是压测JSON解析上限,在很多时候传入一个较大的JSON字符串就可以轻易的绕过RASP和WAF的防御,其本质一方面是性能考虑,另一方面很有可能是RASP或者WAF所使用的JSON解析库根本就不支持大的JSON字符串解析。
- fastjson压测500M以上暂未发现有内存上限;
- 最小的是dsl-json,仅128M;
注:1M = 1024 * 1024
| 名称 | 范围 |
|---|---|
| gson | <512M |
| jackson | <484M |
| fastjson | ∞ |
| fastjson2 | ∞ |
| dsl-json | <=128M |
| org.json | ∞(不稳定) |
| johnzon | <494M |
六、进制转换
。。。
后续内容略。
参考
- https://www.javasec.org/ 【java安全】



